
대망의 팀 프로젝트 과정 마지막 시간입니다.
오늘은 약 5개월 간 진행되었던 Brightics 서포터즈 활동의 마지막 포스팅이기도 한데요. 지난 시간에 1차적으로 R과 Brightics Studio를 통해 분석 모델링 잡업을 진행하였다면, 오늘은 거기에 대한 보충과 정리의 시간입니다.
지난 시간에 R에서 나온 변수들의 VIF 값, Brightics Studio에서 나온 VIF 값이 달라, 변수간 다중공선성을 파악하는 데에 약간의 문제가 있었는데요. Brightics에서는 Split을 미리 적용한 데이터에 Linear Regression 함수를 사용해 VIF 값을 도출한 것이 문제였습니다. 다행히 WorkFlow를 보며 문제를 금새 찾을 수 있었습니다!


Linear Regression Train 함수에서 VIF를 True, VIF Threshold를 10으로 설정하여, R의 결과와 똑같이 cyl, disp, wt 변수에서 다중공선성이 존재함을 확인할 수 있었고, 해당 함수들을 제거하는 과정을 거쳤습니다.
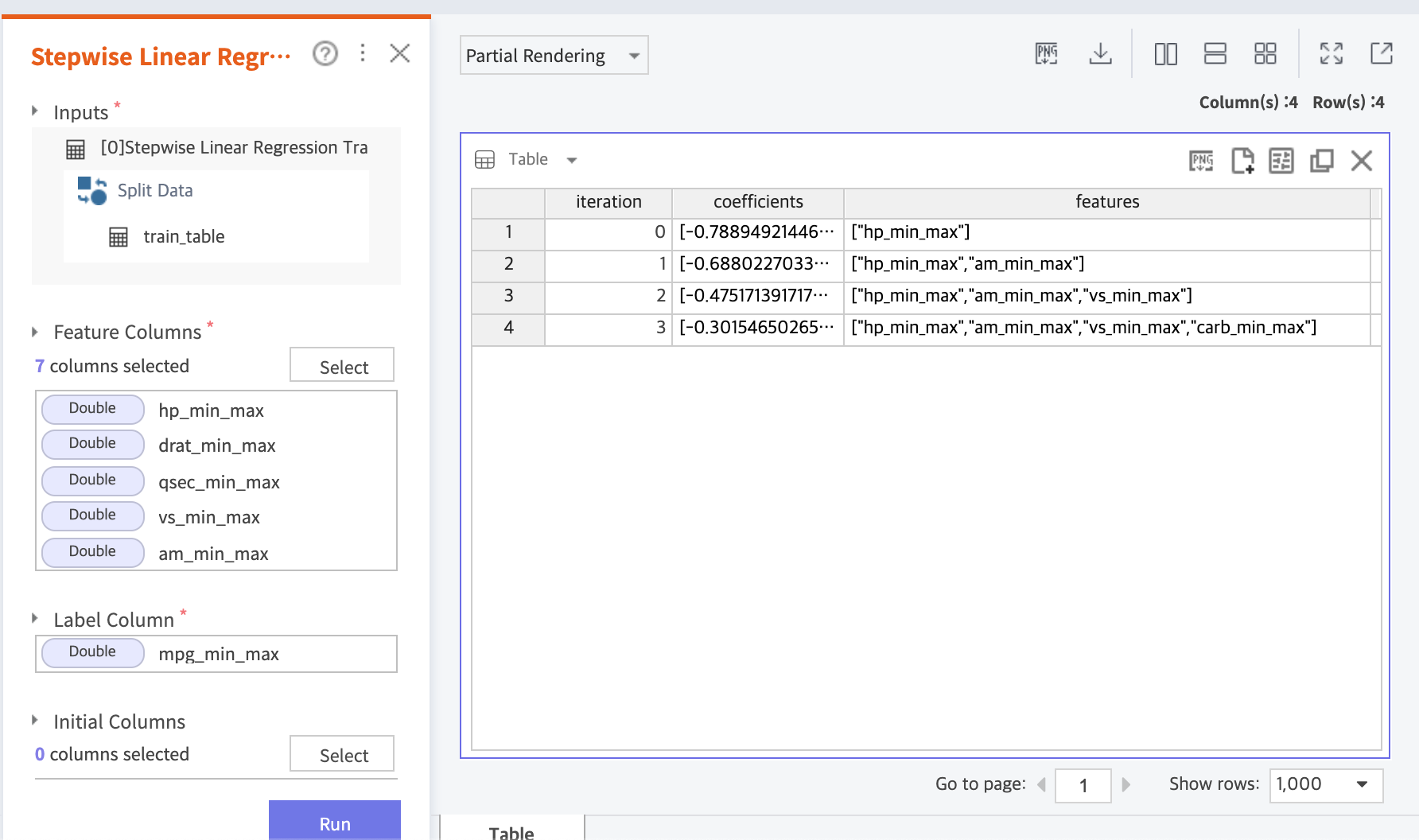
지난 주에서 한 단계 더 나아가, R의 분석 과정과 Brightics의 분석 과정을 완전히 일치시키기 위하여 Linear Regression 함수를 변경하였습니다. 바로 단계적 선택법이 적용된 함수인데요.
R에서는 step 함수를 사용하여, direction을 지정해줌으로서 전진선택법, 후진소거법, 단계적선택법을 선택한 변수 선택을 가능하게 해주며, Brightics의 경우엔 특정 함수에 내장된 Stepwise를 사용해 동일한 방법의 적용이 가능합니다. 이번 모델링에서 사용한 Stepwise Linear Regression Train, Stepwise Linear Regression Predict 함수의 경우 Brightics Studio에서는 제공하지 않으며, Brightics AI를 통해서만 사용이 가능합니다(2020.12월 기준). Brightics AI는 무료체험이 가능하니, 현재로서는 부담없이 이용해볼 수 있습니다!

위와 같이 단계적 선택법, 전진선택, 후진제거를 선택하여 적용 할 수 있습니다. Stepwise Linear Regression Train 함수의 경우 모델 훈련과 동시에 Stepwise를 통해 변수를 선택하므로, R과 완벽히 동일한 프로세스를 적용하긴 어려웠는데요. 하지만 결과를 도출하는 것에는 큰 문제가 없었습니다.

이어서 Stepwise Linear Regression Predict 함수를 적용하였습니다. 이때, Hold Columns에 Label column을 넣어주어야 하는데, 그래야만 해당 column을 함수의 Output에 정적으로 포함시킬 수 있고, 이후 모델 평가 함수에서 사용할 수 있기 때문입니다.
마지막 평가 단계에서 Predict된 값과, 실제 값의 오차 정도를 살펴보겠습니다.


두 모델의 MSE(Mean Squared Error)를 살펴보니, 각각 0.013, 0.008의 수치를 보여주었습니다. 두 모델 모두 큰 차이가 없는 수치로, 두 모델 모두 낮은 MSE 수치를 보여 오차가 비교적 적은 모델임을 알 수 있습니다.


지금까지 작업한 R과 Brightics의 내용입니다. R의 경우 주석을 전체적으로 제거했음에도, 그 분량이 비교적 많으며, 전체적인 프로세스에 익숙하지 않다면 각기 코드만 보고 이해하기에 어려움이 있습니다. 사용법 역시, R은 각 함수의 기본적인 사용법을 잘 알아야하며, 함수에 어떤 인자를 사용해야 하는지, 어떤 형태로 넣어야 하는지 등을 알고 있지 않다면 오류를 경험하기 쉽습니다.

반면에 Brightics의 경우, 각 함수의 이름 자체에서 이미 목적과 기능이 뚜렷이 드러나기 때문에, 통계분석을 경험해보지 않은 초심자라고 해도, 통계적 방법론의 개념만 있다면 충분히 작업 프로세스를 어느정도 이해할 수 있을 것 같습니다. 반면에, Brightics는 정해진 프로세스만 따른다면, 초심자도 큰 문제 없이 일련의 분석 과정의 수행이 가능합니다.

하지만 R은 역시 강력한 도구입니다. 태생부터 통계와 데이터분석에 활용되기 위한 목적을 지녔던 R은 이미 전세계의 통계학자, 데이터과학자들이 만들어낸 무수한 패키지들을 제공받을 수 있고, 앞으로도 빠른 속도로 최신 방법론이 적용되는 것을 기대해볼 수 있습니다. 또한, 프로그래밍 언어의 특성상 굉장히 자유로운 작업이 가능하며, Local 환경과 Server 환경을 가리지 않고, 다양한 모듈과 API를 활용해 어지간한 것들은 전부 구현해낼 수 있습니다.
Brightics는 R에 비해 상대적으로 쉽게 익히고 활용할 수 있지만, 깊게 들어가기에는 약간의 제약 사항이 존재합니다. 스스로 배워야 한다는 점인데요. R과 다르게 Brightics는 아직 사용자가 적으며, 웹상의 콘텐츠 역시 부족한 실정입니다. 공식 Turorial 문서와 Document 페이지를 적극 활용하여 스스로 사용법을 익힐 필요가 있으며, 이중에는 적잖은 시행착오를 겪으며 스스로 체득해야 하는 부분도 있습니다. 사용중 이슈가 발생한다면 사측에 문의하거나, Github(Studio의 경우)로 버그 리포팅을 하여, 사용자가 적극적으로 개선에 기여할 필요도 있습니다. 하지만 시중에 출시된 교재(브라이틱스와 함께하는 데이터분석, Brightics Studio로 시작하는 금융 빅데이터 분석 등)를 이용한다면 러닝커브를 좀 더 짧게 가져갈 수 있으며, 결국 근본적으로 사용법 자체가 어렵지 않기 때문에, 통계적 방법론에 대한 지식이 어느 정도 있으나, 프로그래밍 경험이 전무하고, 당장 분석을 활용해야 하는 유저들에게 많은 장점이 있다고 할 수 있겠습니다.
사실 Brightics 서포터즈 활동과 함께, 학부에서 데이터분석 동아리를 운영하며, 다음에는 오픈소스인 Brightics Studio를 소개하여, 적극 활용해볼 필요가 있겠다는 생각이 들었습니다. Python, R의 경우 단순히 문법을 배우는 것과, 프로그래밍 로직을 배우는 데에만 해도 많은 시간이 들기 때문에, 한정된 시간 동안 데이터 분석과 통계 방법론에 대해 익히는 비중이 줄어들게 된다는 것이 문제였는데요. 차라리 통계 방법론 단계에서는 Brightics Studio를 활용하여 여러 모델들의 분석 프로세스를 심플하고 간결하게 보여준 후에, 코딩을 진행하였으면 강의의 이해도를 끌어올리기에 훨씬 좋지 않았을까 하는 아쉬움도 듭니다.
이렇게 "R 내장데이터(mtcars)를 브라이틱스로 코딩 없이 더 간편하게 분석하기"를 주제로 한 팀 프로젝트도 모두 마무리 되었습니다. R과 Brightics의 장단점, 차이점을 위주로 비교해보는 것이 목적이었는데, 결국 Brightics는 Brightics만의 강력한 장점이 있기에, 기존 데이터 분석에 활용되는 프로그래밍 언어와 비교하기보단, 장점을 극대화하여 사용하는 것이 좋다는 생각이 듭니다.
워낙 많은 경험을 할 수 있었던 서포터즈 활동이라, 추후 조금 더 자세한 후기 포스팅이 곁들여져야 할 것 같습니다.
모쪼록 마지막 포스팅까지 읽어주셔서 감사합니다! :)
본 포스팅은 2020년 삼성SDS Brightics 서포터즈 1기 활동의 일환으로 작성된 포스팅입니다.
'개발하다 > 삼성SDS Brightics 서포터즈 1기' 카테고리의 다른 글
| Brightics 서포터즈 팀 미션 - 분석 모델링 (0) | 2020.11.24 |
|---|---|
| Brightics 서포터즈 팀 미션, 주제 선정 및 데이터 확보 (0) | 2020.11.17 |
| Brightics 서포터즈 개인 미션, 분석 프로젝트 최종 결과 정리 및 레포트 작성 (7) | 2020.11.10 |
| Brightics 서포터즈 개인 미션, 분석 프로젝트 4차 분석 모델링 [최종] (0) | 2020.11.04 |
| Brightics 서포터즈 개인 미션, 분석 프로젝트 3차 분석 모델링 과정 (0) | 2020.11.01 |
